JSON till Dictionary
Du kan enkelt importera en json -formaterad textfil direkt in i ett dictionary i python.
stora mängder data tillgänglig
Det finns hur mycket datafiler som helst ute på internet, som är på json -format. Många API ger också ifrån sig json -formaterat data. Att känna till hur man enkelt kan få in en godtycklig json -fil i ett pythonprogram, för vidare analys, är alltså ganska grundläggande.importera json -fil
Att importera en JSON -formaterad fil in i ett dictionary är enkelt. Du behöver modulen json, dvs skriva import json längst upp i koden, därefter gör 2 rader kod jobbet. Den ena raden pekar ut JSON -filen och den andra skapar dictionary.
import json
fil = open('/json/periodictable.json')
dictionary = json.load(fil)
Du kan också använda kontextoperatorn with.
import json
with open('/json/country_currency_name.json') as fil:
dikt = json.load(fil)
kort repetition
En dictionary i sin enklaste form består av en lista av key:value. Vi kommer åt värdet med t.ex. d["vatten"]. Vi kan också loopa över dictionaryn.
d = {"sten":"hårt", "vatten":"blött"}
print(d["vatten"])
for e in d:
print(e)
En dictionary's value kan vara en lista.
d = {"sten":["hårt","tungt"], "vatten":["blött"]}
for e in d:
print(e,d[e])
En dictionary's value kan vara en lista av dictionarys.
d = {"lärare":[
{"namn":"Kalle","ämne":"Matte"},
{"namn":"Lisa","ämne":"Fysik"}]}
for e in d["lärare"]:
print(e["namn"], "lärare i",e["ämne"])
exempel med importerad data
länder och valutor
Vi börjar med en json -fil som innehåller länder och valutor (json). Vi vill läsa in denna fil och t.ex. räkna ut hur många länder finns där och hur många olika valutor. Filen ser ut som nedan, dvs en lista av dictionaries - eller hur?
Som du ser så är json -filens format i princip identiskt med hur vi beskriver en dictionary.
Vi kan även göra en grafisk representation såhär. Vad vi ser är en lista av dictionarys, som i sin tur innehåller 2 stycken key:value -par.
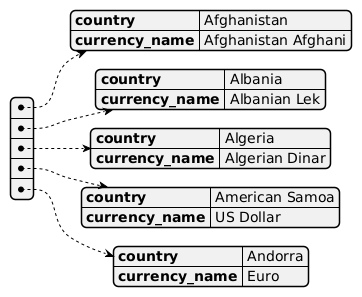
För att räkna ut hur många unika valutor där finns, så behöver vi hålla reda på om vi räknat en valuta eller inte. En slags flagga, så att säga, så att vi inte räknar samma valuta 2 gånger. Så vi kan skapa en tillfällig dictionary i vilken vi lägger in de valutor vi räknat. Om en valuta existerar i denna dictionary, så har vi räknat den. Annars inte.
import json
with open('/json/country_currency_name.json') as fil:
dikt = json.load(fil)
count_flag = {}
count = 0
countries = 0
for c in dikt:
countries += 1
if(count_flag.get(c["currency_name"]) == None):
count_flag[c["currency_name"]] = 1
count += 1
print("Antal olika valutor:", count, "antal länder:",countries)
förväntad livslängd
Json-filen nedan innehåller data om länder och förväntad livslängd (json). Säg att vi vill skapa en funktion som, givet lägsta och högsta ålder, räknar hur många länder som har en förväntad livslängd i detta intervall.
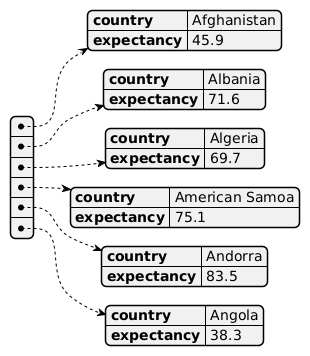
En viktig detalj här, det är att vissa länder saknar uppgift om förväntad livslängd. För dessa länder, på denna post, är värdet None. Vi måste alltså dubbelkolla att det finns ett värde på expectancy.
import json
with open('/json/country_life_expectancy.json') as fil:
dikt = json.load(fil)
def life_expectancy(start_year, end_year):
countries = []
for c in dikt:
if c['expectancy'] is not None:
age = float(c['expectancy'])
if(age > start_year and age < end_year):
countries.append(c)
return("\n".join([x["country"]+', '+str(x["expectancy"])+' år' for x in countries]))
print("Lever kortare än 40 år")
print (life_expectancy(0,40))
print()
print("Längre är 80 år")
print (life_expectancy(80,150))
Blir du tokig på raden
Läs mer om generatorer i python här.
Vi har en fil med länder och språk (json). I många länder pratas flera språk. Vi vill veta hur många språk det finns totalt i denna lista av länder. Steg 1 är att försöka förstå hur vi ska läsa filen.

[x["country"]+', '+str(x["expectancy"])+' år' for x in countries]
Läs mer om generatorer i python här.
länder och språk (tentauppgift)
Vi har en fil med länder och språk (json). I många länder pratas flera språk. Vi vill veta hur många språk det finns totalt i denna lista av länder. Steg 1 är att försöka förstå hur vi ska läsa filen.
import json
with open('/json/country_languages.json') as fil:
dikt = json.load(fil)
for c in dikt:
print(c['country'], end =": ")
for l in c['languages']:
print(l, end=", ")
print()
Vi vill räkna alla språk. Vi vill bara räkna varje språk 1 gång. Så vi behöver en dictionary som håller koll på vilka språk vi räknat.
Så vi loopar över alla länder och för varje land loopar vi över alla språk där talas. För varje språk, så tittar i vår temporära flagg dictionary om vi har räknat språket genom att kolla om det existerar där. Om det inte existerar, så har vi inte räknat det och då räknar vi det samt lägger till det i dictionaryn.
Så vi loopar över alla länder och för varje land loopar vi över alla språk där talas. För varje språk, så tittar i vår temporära flagg dictionary om vi har räknat språket genom att kolla om det existerar där. Om det inte existerar, så har vi inte räknat det och då räknar vi det samt lägger till det i dictionaryn.
import json
with open('/json/country_languages.json') as fil:
dikt = json.load(fil)
count_flag = {}
count_lang = 0
countries = 0
for c in dikt:
countries += 1
for l in c['languages']:
if (count_flag.get(l) == None):
count_flag[l]=1
count_lang += 1
print(f"{countries} länder och {count_lang} språk")
i vilka länder talas ett språk?
Vi har fortfarande vår fil med länder och språk (json). Nu vill vi istället veta i vilka länder ett visst språk talas.
import json
with open('/json/country_languages.json') as fil:
dikt = json.load(fil)
def speak_lang(lang):
countries = []
for c in dikt:
this = False
for l in c['languages']:
if (l == lang):
this = True
if(this == True):
countries.append(c['country'])
return(countries)
print("Länder där Swedish talas")
print(speak_lang("Swedish"))
print("Länder där English talas")
print(speak_lang("English"))
print("Länder där Spanish talas")
print(speak_lang("Spanish"))
print("Länder där Chinese talas")
print(speak_lang("Chinese"))
Vi har även en fil med länder och population (json) så vi borde kunna räkna befolkningen där ett språk talas. Okej, nu kommer detta inte stämma jättebra med verkligheten förstås, men kan vara en kul uppgift ändå.
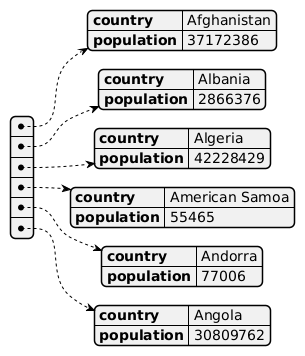
Så, vi vill addera befolkningen i de länder som talar ett visst språk. För att snabbt komma åt hur stor befolkning ett land har, så låt oss skapa en enkelt dictionary där key : value är land : befolkning. Annars behöver vi loopa igenom dictionaryn med länder och befolkning varje gång vi har en fråga om befolkning. Studera nedan kod.
Så, vi vill addera befolkningen i de länder som talar ett visst språk. För att snabbt komma åt hur stor befolkning ett land har, så låt oss skapa en enkelt dictionary där key : value är land : befolkning. Annars behöver vi loopa igenom dictionaryn med länder och befolkning varje gång vi har en fråga om befolkning. Studera nedan kod.
import json
with open('/json/country_languages.json') as fil:
country_languages = json.load(fil)
with open('/json/country_population.json') as fil:
country_population = json.load(fil)
population = {}
for c in country_population:
population[c['country']]=c['population']
def speak_lang_pop(lang):
pop = 0
for c in country_languages:
this = False
for l in c['languages']:
if (l == lang):
this = True
if(this == True):
pop += population[c['country']]
return(pop)
print("Befolkning i länder där Swedish talas")
print(speak_lang_pop("Swedish"))
print("Befolkning i länder där English talas")
print(speak_lang_pop("English"))
print("Befolkning i länder där Spanish talas")
print(speak_lang_pop("Spanish"))
print("Befolkning i länder där Chinese talas")
print(speak_lang_pop("Chinese"))
periodiska systemet
På github ligger ett projekt som samlar data om periodiska systemet. [här]
JSON -filen är redan nerladdad och i programmet nedan läser vi in denna fil.
Du kan se JSON -filen genom att klicka här. Öppnas i ny flik i webbläsarens JSON-läsare.
JSON -filens struktur (vilket är samma struktur som vår dictionary sedan får) ser ut som nedan. Vi har alltså som i exemplet med lärare ovan, en dictionary som är en lista av dictionarys. På toppnivån finns bara en enda key:value. Key är "elements" och value är en lista av dictionarys.
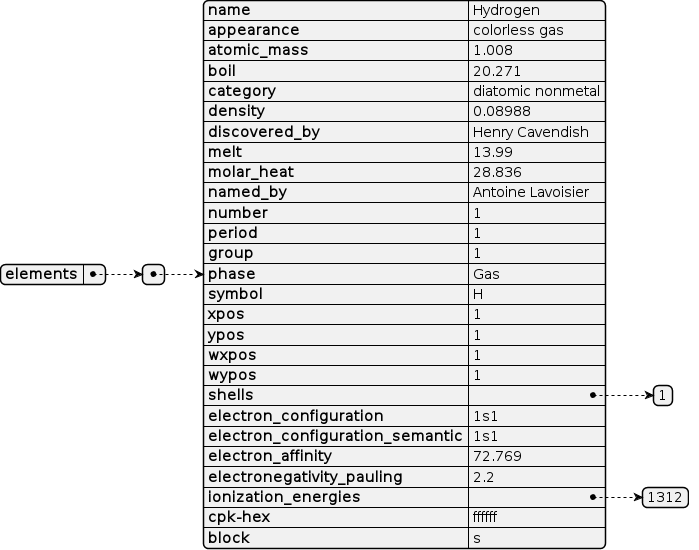
Periodiska systemet
Nedan ett litet urklipp ur denna fil. Ytterst har vi faktiskt en dictionary { ... }. I denna dictionary finns ett key : value -par ser det ut som. Dvs en key elements vars value är en lista [ ... ] av dictionaries.
{ "elements" : [{...}, {...}, {...}, ...] }

Det är otroligt viktigt att man inte hoppar över denna analys. Varje inre dictionary representerar ett ämne i periodiska systemet. Med key som name (dess namn), atomic_mass (massan), shells en lista som är skalen runt kärnan med antal elektroner.
Så hur kommer vi då åt dessa data? Säg att vi döper dictionaryn till periodiska. Denna dictionary kommer i första nivån bara innehålla en variabel och det är "elements".
periodiska["elements"]
Denna variabel är en lista (av ämnen) så vi kommer åt dem med dess index.
periodiska["elements"][0]
Detta är första ämnet. Vi kan prova printa ut ...
periodiska["elements"][0]["name"]
periodiska = {
"elements": [
{
"name": "Hydrogen",
"appearance": "colorless gas",
"atomic_mass": 1.008,
"boil": 20.271,
"category": "diatomic nonmetal",
"density": 0.08988,
"melt": 13.99,
"molar_heat": 28.836,
"named_by": "Antoine Lavoisier",
"number": 1,
"period": 1,
"group": 1,
"phase": "Gas",
"symbol": "H",
"xpos": 1,
"ypos": 1,
"wxpos": 1,
"wypos": 1,
"shells": [
1
]
},
{
"name": "Helium",
"appearance": "colorless gas",
"atomic_mass": 4.0026022,
"boil": 4.222,
"category": "noble gas",
"density": 0.1786,
"melt": 0.95,
"molar_heat": None,
"named_by": None,
"number": 2,
"period": 1,
"group": 18,
"phase": "Gas",
"symbol": "He",
"xpos": 18,
"ypos": 1,
"wxpos": 32,
"wypos": 1,
"shells": [
2
]
},
{
"name": "Lithium",
"appearance": "silvery-white",
"atomic_mass": 6.94,
"boil": 1603,
"category": "alkali metal",
"density": 0.534,
"melt": 453.65,
"molar_heat": 24.86,
"named_by": None,
"number": 3,
"period": 2,
"group": 1,
"phase": "Solid",
"symbol": "Li",
"xpos": 1,
"ypos": 2,
"wxpos": 1,
"wypos": 2,
"shells": [
2,
1
]
},
{
"name": "Beryllium",
"appearance": "white-gray metallic",
"atomic_mass": 9.01218315,
"boil": 2742,
"category": "alkaline earth metal",
"density": 1.85,
"melt": 1560,
"molar_heat": 16.443,
"named_by": None,
"number": 4,
"period": 2,
"group": 2,
"phase": "Solid",
"symbol": "Be",
"xpos": 2,
"ypos": 2,
"wxpos": 2,
"wypos": 2,
"shells": [
2,
2
]
}
]
}
print(periodiska["elements"][0]["name"])
print(periodiska["elements"][3]["shells"])
print(periodiska["elements"][3]["name"])
print(periodiska["elements"][3]["shells"])
Med 2 rader kod kan vi ladda in en stor dictionary som finns på en fil. Du kan titta på själva filen här (öppnas i nytt fönster). Det är data i föregående exempel, fast hela periodiska systemet.
fil = open('/json/periodictable.json')
per = json.load(fil)
import json
fil = open('/json/periodictable.json')
per = json.load(fil)
for i in range(0,len(per['elements'])):
namn = per["elements"][i]["name"]
nummer = per["elements"][i]["number"]
mass = per["elements"][i]["atomic_mass"]
fas = per["elements"][i]["phase"]
print("{:<3} {:<14} {:<7} {:<8}".format(nummer,namn,fas,mass))
fil.close()
I filen finns information om antalet elektroner i varje skal. Det är key : value -paret shells som består av lista. Vi kanske vill skriva ut denna.
Om en dictionary har många nivåer, så kan det bli tydligare om man istället för att loopa igenom med index, istället loopar igenom objekten. Då blir det lite mindre kod som kan gå fel.
Om en dictionary har många nivåer, så kan det bli tydligare om man istället för att loopa igenom med index, istället loopar igenom objekten. Då blir det lite mindre kod som kan gå fel.
import json
fil = open('/json/periodictable.json')
per = json.load(fil)
for e in per['elements']:
namn = e["name"]
nummer = e["number"]
skal = ' '.join(str(x) for x in e["shells"])
print("{:<3} {:<14} {:<14}".format(nummer,namn,skal))
fil.close()
Vi kan plocka ut alla ämnen i gas -form. Vi skapar en ny lista enbart med de element som är i gasform.
import json
fil = open('/json/periodictable.json')
per = json.load(fil)
fil.close()
def phase(ph):
svar = []
for e in per['elements']:
if(e["phase"] == ph):
svar.append(e)
return(svar)
gasform = phase("Gas")
for e in gasform:
namn = e["name"]
nummer = e["number"]
skal = ' '.join(str(x) for x in e["shells"])
print("{:<3} {:<14} {:<14}".format(nummer,namn,skal))
Ovan kan med python generator -uttryck också skrivas såhär.
import json
fil = open('/json/periodictable.json')
per = json.load(fil)
fil.close()
gaser = ", ".join(e["name"] for e in per['elements'] if e["phase"] == 'Gas')
print(gaser)
Eller såhär, så vi tydligare ser vilket atomnummer det är.
import json
fil = open('/json/periodictable.json')
per = json.load(fil)
fil.close()
gaser = ", ".join(e["name"]+'('+str(e["number"])+')' for e in per['elements'] if e["phase"] == 'Gas')
print(gaser)
Stämmer det ?

Som du ser är dictionary väldigt kraftfullt, i synnerhet i kombination med enkelheten att hämta in stora mängder data på JSON -format.
Låt oss gör något spännande. Vi kan t.ex. skapa en sorterad lista utifrån ämnen och dess elektronegativitet.
Först skapar vi en ny nerbantad lista av dictionaries, med namn, nummer och elektronegativitet, som vi kallar elektro där alla ämnen med en elektronegativtet angiven finns.
Därefter sorterar vi denna lista. För att kunna använda den inbyggda sorteringsfunktionen måste vi skriva en funktion som plockar ut nyckeln vi ska sortera på (key).
När vi sorterat, så skriver vi ut listan.
Som du ser är dictionary väldigt kraftfullt, i synnerhet i kombination med enkelheten att hämta in stora mängder data på JSON -format.
elektonegativitet
Låt oss gör något spännande. Vi kan t.ex. skapa en sorterad lista utifrån ämnen och dess elektronegativitet.
Först skapar vi en ny nerbantad lista av dictionaries, med namn, nummer och elektronegativitet, som vi kallar elektro där alla ämnen med en elektronegativtet angiven finns.
Därefter sorterar vi denna lista. För att kunna använda den inbyggda sorteringsfunktionen måste vi skriva en funktion som plockar ut nyckeln vi ska sortera på (key).
När vi sorterat, så skriver vi ut listan.
import json
fil = open('/json/periodictable.json')
per = json.load(fil)
elektro = []
for i in range(0,len(per['elements'])):
namn = per["elements"][i]["name"]
nummer = per["elements"][i]["number"]
el = per["elements"][i].get("electronegativity_pauling",None)
if(el!=None):
elektro.append({"name":namn,"number":nummer,"electronegativity_pauling":el})
def electronegativity(n):
return n["electronegativity_pauling"]
elektro_sorted = sorted(elektro, key=electronegativity, reverse=True)
print("Elektronegativitet")
for i in range(0,len(elektro_sorted)):
namn = elektro_sorted[i]["name"]
nummer = elektro_sorted[i]["number"]
el = elektro_sorted[i]["electronegativity_pauling"]
print("{:<3} {:<14} {:} ".format(nummer,namn,el))
fil.close()
tentauppgift
En variant på tentauppgift följer. Så, du ska skriva en funktion som beräknar massan av en molekyl. Dvs, du ska slå upp atomens massa och eventuellt multiplicera med antalet av denna atom. Så massan av H2SO3 är H * 2 + S + O * 3. Vi kan betrakta indata som en sträng och utnyttja att multiplikatorn alltid kommer efter atomen och vi kan anta att multiplikatorn bara är en (1st) siffra 2-9.
Det finns många sätt skriva algoritmen. Ett sätt är att loopa över strängen. Om tecknet är en bokstav, då är det en atom, dvs vi kollar upp vikten och lägger vikten i en lista. Om tecknet i strängen är en siffra, så multiplicerar vi senast ditlagda vikt i vår lista med denna multipel. Slutligen summerar vi alla vikter i vår lista och returnerar svaret.
För att ovan ska fungera behövs en liten hjälp-dictionary. Vi sparar undan atomernas massa i en dictionary som heter vikt, så vi enkelt kan slå upp vikten i vår dictionary.
import json
fil = open('/json/periodictable.json')
per = json.load(fil)
fil.close()
vikt = {}
for e in per['elements']:
m = e["atomic_mass"]
sym = e["symbol"]
vikt[sym]=m
def mass(molekyl):
molekylvikt=[]
for m in molekyl:
if(m.isnumeric()):
molekylvikt[-1] = molekylvikt[-1] * float(m)
else:
molekylvikt.append(float(vikt[m]))
return(round(sum(molekylvikt),2))
print("H2O",mass("H2O"),"g/mol")
print("CH4",mass("CH4"),"g/mol")
print("H2SO3",mass("H2SO3"),"g/mol")
En utvecklad version av denna uppgift som tar alla atomer och alla multipler, samt en textfil med atomer och massa.
lite frågor ...
För att enkelt läsa in en json -fil i en dictionary måste vi importera
import jonson
import json
import open
import dictionary
Efter att vi importerat biblioteket så öppnar vi filen. Hur gör vi det?
open= json(filnamn)
import = jonson(open)
fil = open(filnamn)
dictionary=filnamn(open)
Det tredje steget för att få in jsonfilen i en dictionary är
load = dictionary(json)
dictionary = load.jonson(fil)
dictionary = json.load(fil)
json = load(jonsson)